
In progressive software engineering firms it has become common to blur the line between the creation of the software product and the operation of that product.
Google is credited with popularizing this practice by codifying the term "Site Reliability Engineering" and hiring a team of software engineers to operate a data center and the associated applications in it.
Prior to this it was common to have a strong separation between product development and business operations. Operations would staff and manage IT and Customer Support. Engineering, design, and product-specific folks would staff and manage product development.
Mark Burgess writes, in "Site Reliability Engineering":
Google grew at a time when the traditional role of the system administrator was being transformed. It questioned system administration, as if to say: we can't afford to hold tradition as an authority, we have to think anew, and we don't have time to wait for everyone else to catch up. In the introduction to Principles of Network and System Administration, I claimed that system administration was a form of human-computer engineering. This was strongly rejected by some reviewers, who said "we are not yet at the stage where we can call it engineering." At the time, I felt that the field had become lost, trapped in its own wizard culture, and could not see a way forward. Then, Google drew a line in the silicon, forcing that fate into being. The revised role was called SRE, or Site Reliability Engineer. Some of my friends were among the first of this new generation of engineer; they formalized it using software and automation.
Capitalist organizations are designed to increase capital efficiency. They create more output at a lower cost. Google is in the business of delivering advertisements. Every hour spent administering a database is overhead, so they designed databases that don't need administering and systems that could survive an entire data center going off line. They used software engineering, computer science and excellent systems architecture to obviate the need for systems administration. Operations that scale linearly with output are the norm and efficient operational organizations are the exception.
Google improved operating efficiency by applying engineering disciplines to operations tasks.
In resource efficiency terms: good operations teams grow much slower than the output of the organization that needs them. Mediocre operations teams grow linearly. Bad teams consume more over time than their output grows.
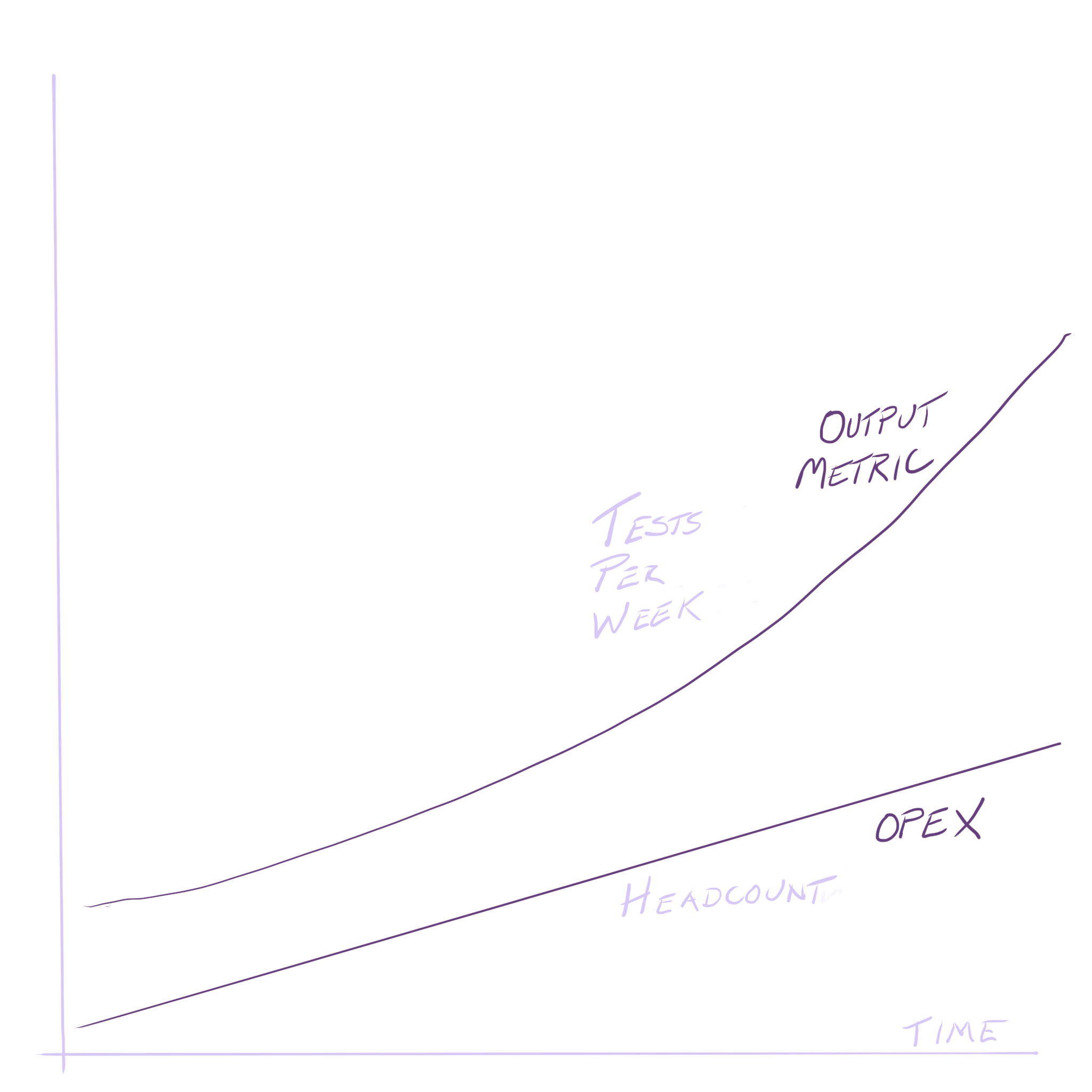
Operations of every sort can improve by regularly considering this practice. Operations should usually have an ordered list of goals with associated metrics like "reliability", "resource efficiency". Resource efficiency is split into capital expenses and operating expenses. Can you reduce the amount of person-labor by putting a task into computer-labor (automation?) How? What sort of engineering tasks would you need to do? Is your current team capable of evaluating that? Is your current team capable of executing on it?
Some organizations take this practice in a different direction. Instead of creating operations teams full of engineers, it has become common for software development teams to "own their uptime". This means they are entirely responsible for operating their products. The development team intimately knows the failure modes and inefficiencies of the things they make, and are charged with dealing with them. This can obviously backfire if the team is not properly supported and resourced from the organization. Done well it creates a feedback loop which enforces constant improvement. I've also only seen this work with software teams responsible for one installation of their software, like web applications.
This usually requires adding some specialists to your team, and cross-training between folks who have previously specialized in operations or development.
What both of these approaches have in common that is exceptional is leveraging software engineering practices to automate operational tasks.
If you take it as a given that automation improves operational efficiency, and that operational efficiency is a goal of a capitalist organization (I do) then you must invest in automation at every level.
As an individual on an operations team at a capitalist organization you need to ask what things you spend time on that you could spend less time on. What could be automated with monitoring tools instead of daily check lists? What would that monitoring tool look like? Can you identify items that are Unstructured Individual Tasks and move them into procedures or other tools?
As a manager of an operations team you need to be acutely aware of what tasks your team members spend time on. Do tools exist that could help them? Can tools be created? Can the system be improved such that items on the list can be removed or moved up the hierarchy?
No matter what: make a baseline and measure your results. Engineering disciplines are primarily about the judicious application of the scientific method paired with some desired outcome. Measure what you want to improve.
Requires no human operations or oversight. Resilient reliable systems often have many of these properties. Example: When available RAM on a distributed database node drops below 5% move it to a bigger node and write it down in the log.
Requires a human operator with minimal training to oversee automated operations. Most monitoring falls in this category. An expert identifies a situation that requires intervention and attaches a monitor to that metric. Example: When available RAM on THE MASTER DATABASE falls below 5% then call the expert!
A human operator runs a procedure with minimal training. Example: Log in to the server monitoring website and write down the RAM usage on every server. Email the Database Administrator if any of them are over 4889882kB
Requires a human operator with specialized knowledge or expertise or a lot of training. Many DevOps tools, and especially dashboard tools fall into this category and require expert operators. They are often major improvements over things further down the stack. Example: When I, The Database Administrator, log into my computer: run the script that checks the cluster health
An expert runs a checklist that they or another expert created. Example: To deploy the new software version: log into the server, check the clock, pull from github, restart apache.
Operators and Experts doing everyday checkups and tasks. Experts dealing with unexpected problems typically fall into this category. This is most of what "debugging" is. It's not very efficient.
Team gets together at a specific time to do a specific thing. It's obvious who is required and what the objectives are. There are expected outcomes. Some organizations still deploy software this way. "At 4P on Wednesday, the operations team deploys the new software version".
These are meetings with agendas. Board meetings. Sprint Planning. Stand Ups. They're often required and tremendously useful in some situations.
These are meetings without agendas. They might make you feel good, but they're probably not nearly as useful as you think. Avoid in work situations.
Thank you Jane Davis, Kevin Sturdevant, and Chris Hoffman for reading drafts of this post
Kevin also had this to say, which I thought was worth including in whole:
I think it goes beyond automation to include general efficiency and ownership. See something that could be better? Get a baseline, improve it, put it on your resume. See something that isn't covered? Cover it, then make it a position, then argue that it should really be a department.
7th July 2018
I won't ever give out your email address. I don't publish comments but if you'd like to write to me then you could use this form.
I'm Issac. I live in Oakland. I make things for fun and money. I use electronics and computers and software. I manage teams and projects top to bottom. I've worked as a consultant, software engineer, hardware designer, artist, technology director and team lead. I do occasional fabrication in wood and plastic and metal. I run a boutique interactive agency with my brother Kasey and a roving cast of experts at Kelly Creative Tech. I was the Director of Technology for Nonchalance during the The Latitude Society project. I was the Lead Web Developer and then Technical Marketing Engineer at Nebula, which made an OpenStack Appliance. I've been building things on the web and in person since leaving Ohio State University's Electrical and Computer engineering program in 2007. Lots of other really dorky things happened to me before that, like dropping out of high school to go to university, getting an Eagle Scout award, and getting 6th in a state-wide algebra competition. I have an affinity for hopscotch.